Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
-
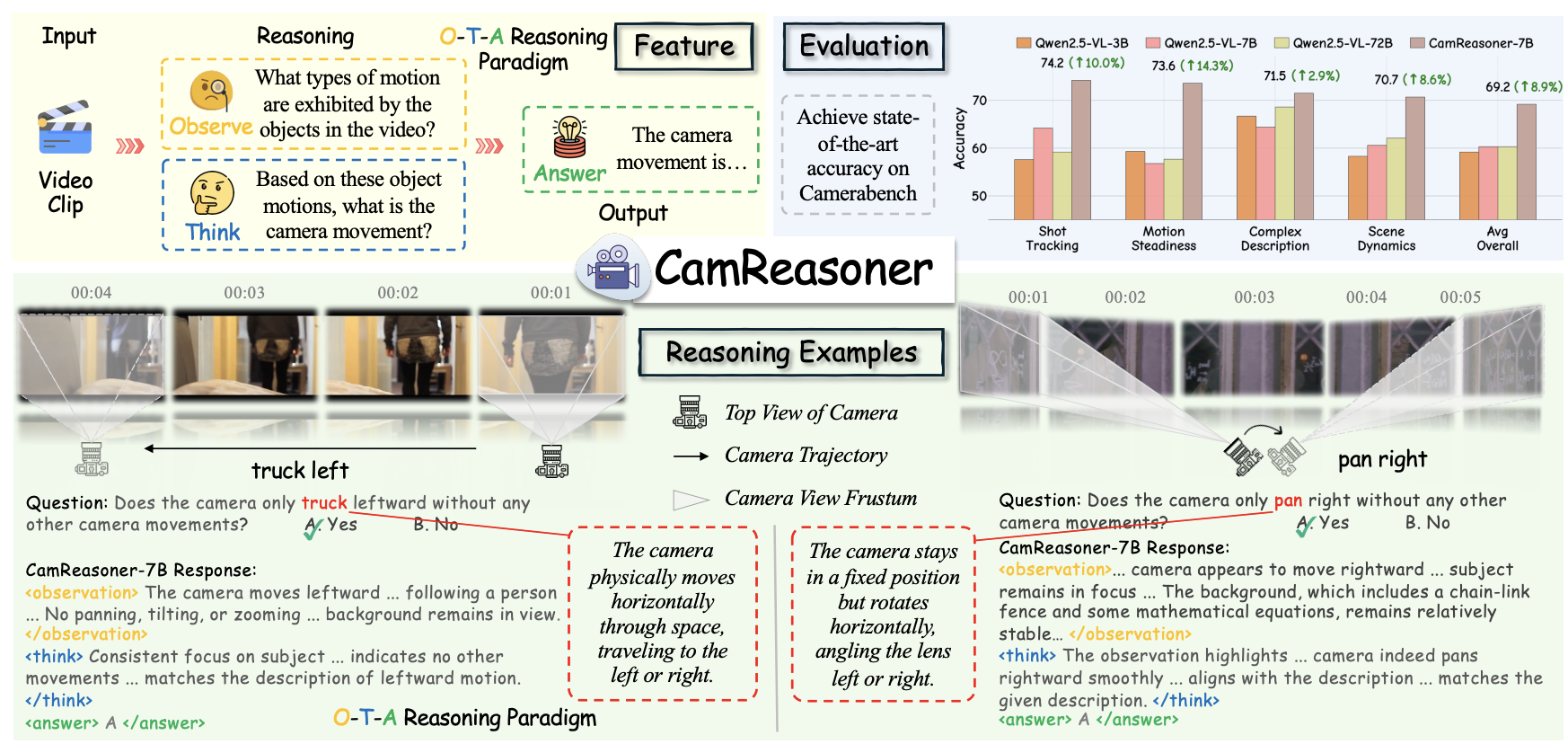 CamReasoner: Reinforcing Camera Movement Understanding via Structured Spatial ReasoningHang Wu, Yujun Cai, Zehao Li, and 4 more authorsIn ICML, 2026Under review.
CamReasoner: Reinforcing Camera Movement Understanding via Structured Spatial ReasoningHang Wu, Yujun Cai, Zehao Li, and 4 more authorsIn ICML, 2026Under review.Understanding camera dynamics is a fundamental pillar of video spatial intelligence. However, existing multimodal models predominantly treat this task as a black-box classification, often confusing physically distinct motions by relying on superficial visual patterns rather than geometric cues. We present CamReasoner, a framework that reformulates camera movement understanding as a structured inference process to bridge the gap between perception and cinematic logic. Our approach centers on the Observation-Thinking-Answer (O-T-A) paradigm, which compels the model to decode spatio-temporal cues such as trajectories and view frustums within an explicit reasoning block. To instill this capability, we construct a Large-scale Inference Trajectory Suite comprising 18k SFT reasoning chains and 38k RL feedback samples. Notably, we are the first to employ RL for logical alignment in this domain, ensuring motion inferences are grounded in physical geometry rather than contextual guesswork. By applying Reinforcement Learning to the Observation-Think-Answer (O-T-A) reasoning paradigm, CamReasoner effectively suppresses hallucinations and achieves state-of-the-art performance across multiple benchmarks.
-
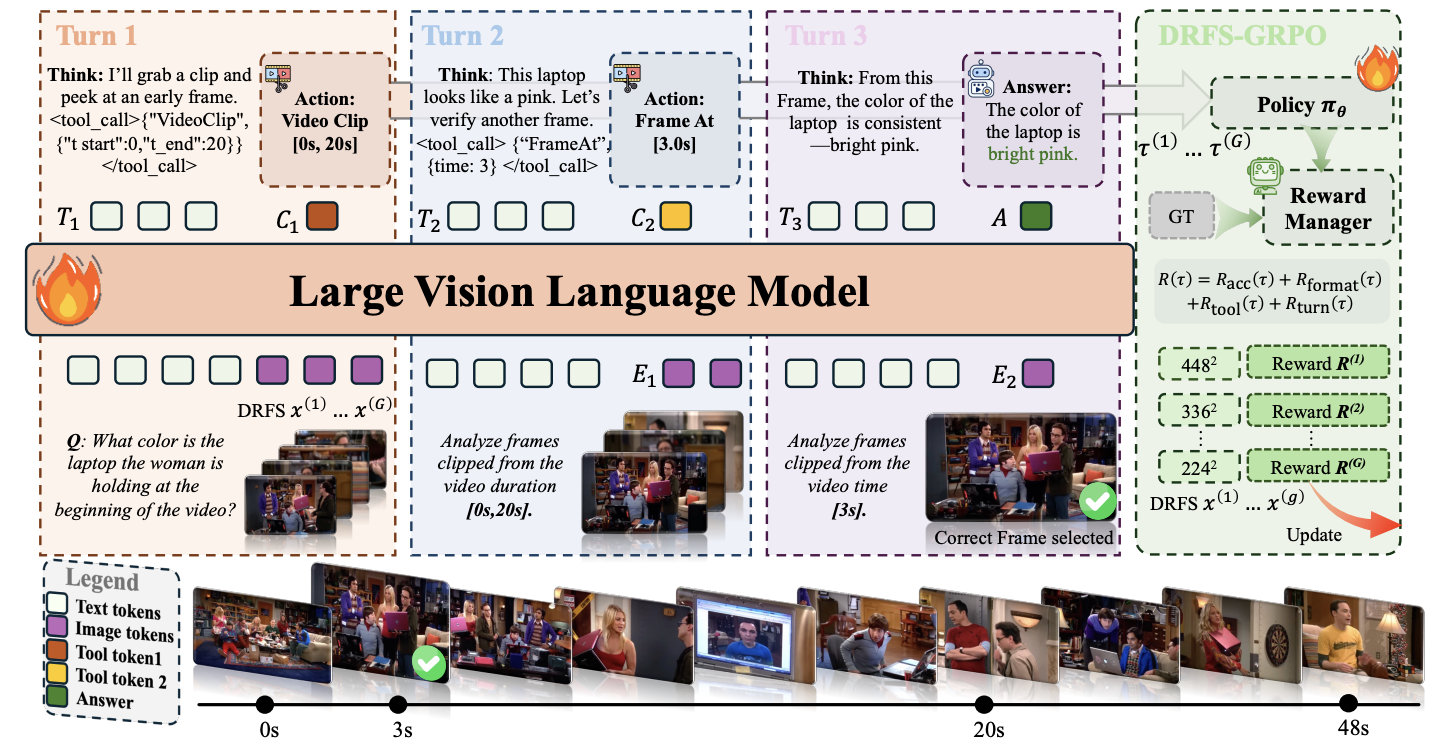 FrameMind: Frame-Interleaved Video Reasoning via Reinforcement LearningHaonan Ge, Yiwei Wang, Kai-Wei Chang, and 2 more authorsIn ICLR, 2026Under review.
FrameMind: Frame-Interleaved Video Reasoning via Reinforcement LearningHaonan Ge, Yiwei Wang, Kai-Wei Chang, and 2 more authorsIn ICLR, 2026Under review.Current video understanding models rely on fixed frame sampling strategies, processing predetermined visual inputs regardless of the specific reasoning requirements of each question. This static approach limits their ability to adaptively gather visual evidence, leading to suboptimal performance on tasks that require either broad temporal coverage or fine-grained spatial detail. In this paper, we introduce FrameMind, an end-to-end framework trained with reinforcement learning that enables models to dynamically request visual information during reasoning through Frame-Interleaved Chain-of-Thought (FiCOT). Unlike traditional approaches, FrameMind operates in multiple turns where the model alternates between textual reasoning and active visual perception, using tools to extract targeted frames or video clips based on identified knowledge gaps. To train effective dynamic sampling policies, we propose Dynamic Resolution Frame Sampling (DRFS), which exposes models to diverse temporal-spatial trade-offs during learning, and DRFS-GRPO, a group-relative policy optimization algorithm that learns from outcome-based rewards without requiring frame-level annotations. Extensive experiments on challenging benchmarks like MLVU and VideoMME demonstrate that our method significantly outperforms existing models, advancing the state of the art in flexible and efficient video understanding.
- ICLR
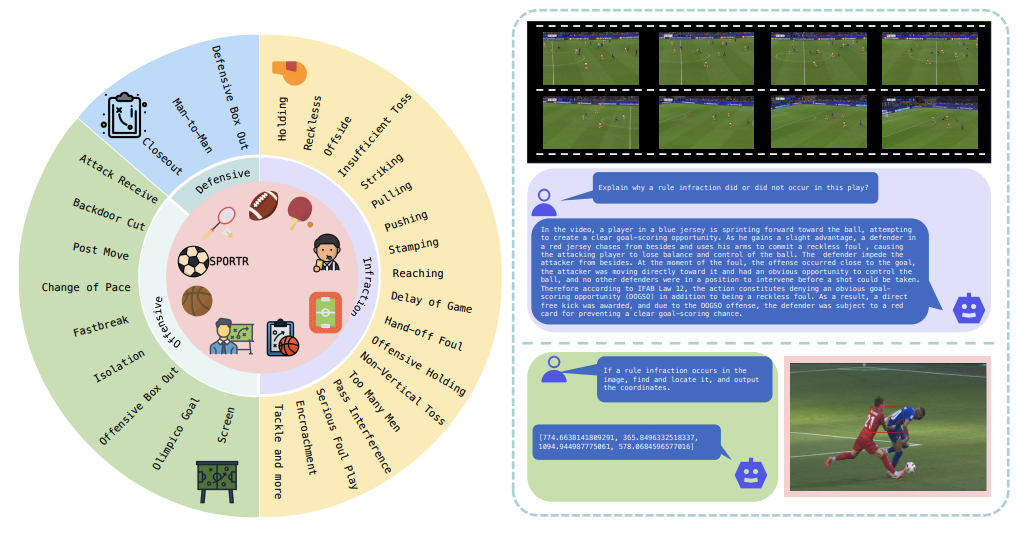 SportR: A Benchmark for Multimodal Large Language Model Reasoning in SportsHaotian Xia*, Haonan Ge*, Junbo Zou*, and 16 more authorsIn ICLR, 2026
SportR: A Benchmark for Multimodal Large Language Model Reasoning in SportsHaotian Xia*, Haonan Ge*, Junbo Zou*, and 16 more authorsIn ICLR, 2026Artificial Intelligence brings powerful new tools to sports, from automated officiating to tactical analysis, but these applications all depend on a core reasoning capability. Deeply understanding sports requires an intricate blend of fine-grained visual perception and rule-based reasoning—a challenge that pushes the limits of current multimodal models. To succeed, models must master three critical capabilities: perceiving nuanced visual details, applying abstract sport rule knowledge, and grounding that knowledge in specific visual evidence. Current sports benchmarks either cover single sports or lack the detailed reasoning chains and precise visual grounding needed to robustly evaluate these core capabilities in a multi-sport context. To address this gap, we introduce SportR, the first multi-sports large-scale benchmark designed to train and evaluate MLLMs on the fundamental reasoning required for sports intelligence. Our benchmark provides a dataset of 5,017 images and 2,101 videos. To enable granular evaluation, we structure our benchmark around a progressive hierarchy of question-answer (QA) pairs designed to probe reasoning at increasing depths—from simple infraction identification to complex penalty prediction. For the most advanced tasks requiring multi-step reasoning, such as determining penalties or explaining tactics, we provide 7,118 high-quality, human-authored Chain-of-Thought (CoT) annotations. In addition, our benchmark incorporates both image and video modalities and provides manual bounding box annotations to directly test visual grounding in the image part. Extensive experiments demonstrate the profound difficulty of our benchmark. State-of-the-art baseline models perform poorly on our most challenging tasks. While training on our data via Supervised Fine-Tuning and Reinforcement Learning improves these scores, they remain relatively low, highlighting a significant gap in current model capabilities. SportR presents a new challenge for the community, providing a critical resource to drive future research in multimodal sports reasoning.
-
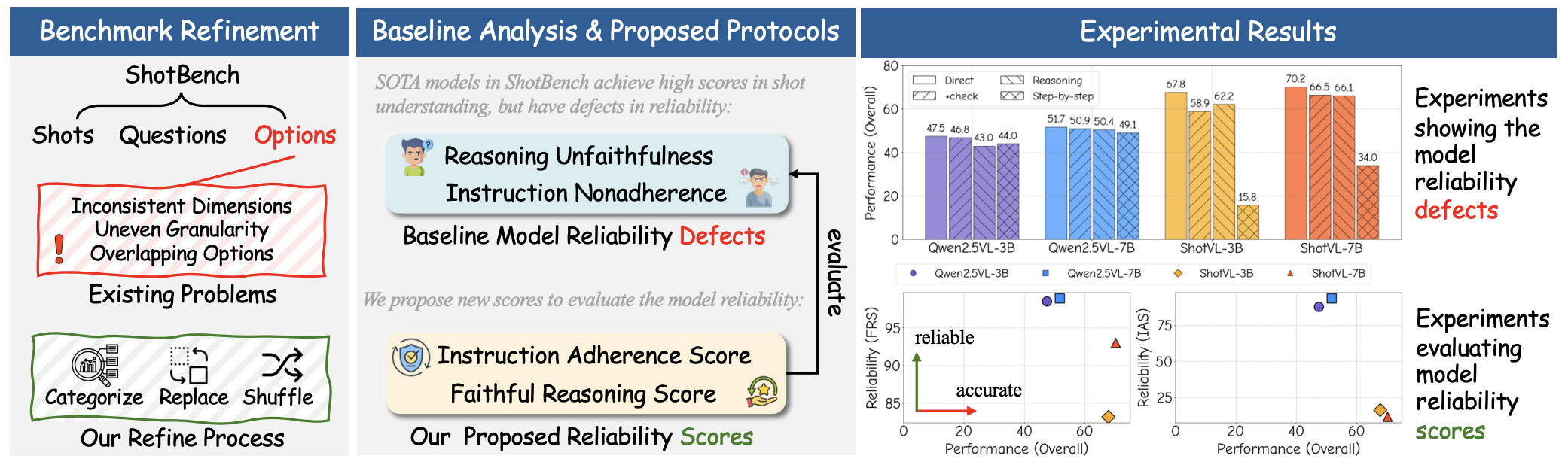 RefineShot: Rethinking Cinematography Understanding with Foundational Skill EvaluationHang Wu, Yujun Cai, Haonan Ge, and 3 more authorsIn ICLR, 2026Under review.
RefineShot: Rethinking Cinematography Understanding with Foundational Skill EvaluationHang Wu, Yujun Cai, Haonan Ge, and 3 more authorsIn ICLR, 2026Under review.Cinematography understanding refers to the ability to recognize not only the visual content of a scene but also the cinematic techniques that shape narrative meaning. This capability is attracting increasing attention, as it enhances multimodal understanding in real-world applications and underpins coherent content creation in film and media. As the most comprehensive benchmark for this task, ShotBench spans a wide range of cinematic concepts and VQA-style evaluations, with ShotVL achieving state-of-the-art results on it. However, our analysis reveals that ambiguous option design in ShotBench and ShotVL’s shortcomings in reasoning consistency and instruction adherence undermine evaluation reliability, limiting fair comparison and hindering future progress. To overcome these issues, we systematically refine ShotBench through consistent option restructuring, conduct the first critical analysis of ShotVL’s reasoning behavior, and introduce an extended evaluation protocol that jointly assesses task accuracy and core model competencies. These efforts lead to RefineShot, a refined and expanded benchmark that enables more reliable assessment and fosters future advances in cinematography understanding.
2025
- EMNLP
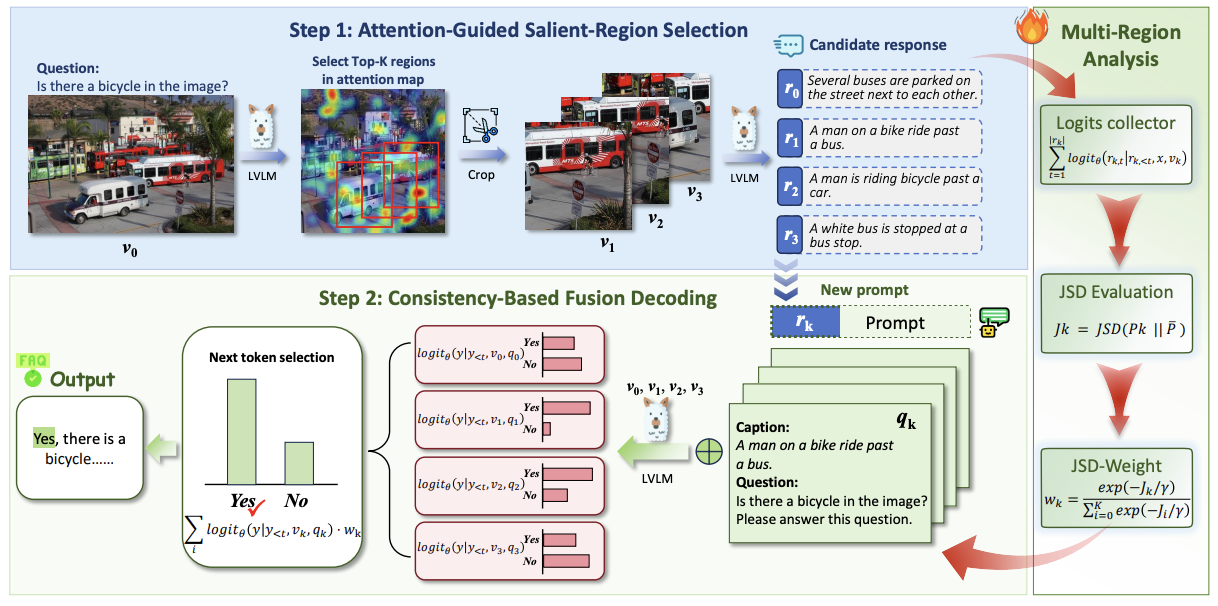 MRFD: Multi-Region Fusion Decoding with Self-Consistency for Mitigating Hallucinations in LVLMsHaonan Ge, Yiwei Wang, Ming-Hsuan Yang, and 1 more authorIn EMNLP, 2025
MRFD: Multi-Region Fusion Decoding with Self-Consistency for Mitigating Hallucinations in LVLMsHaonan Ge, Yiwei Wang, Ming-Hsuan Yang, and 1 more authorIn EMNLP, 2025Large Vision-Language Models (LVLMs) have shown strong performance across multimodal tasks. However, they often produce hallucinations – text that is inconsistent with visual input, due to the limited ability to verify information in different regions of the image. To address this, we propose Multi-Region Fusion Decoding (MRFD), a training-free decoding method that improves factual grounding by modeling inter-region consistency. MRFD identifies salient regions using cross-attention, generates initial responses for each, and computes reliability weights based on Jensen-Shannon Divergence (JSD) among the responses. These weights guide a consistency-aware fusion of per-region predictions, using region-aware prompts inspired by Chain-of-Thought reasoning. Experiments across multiple LVLMs and benchmarks show that MRFD significantly reduces hallucinations and improves response factuality without requiring model updates.